
Meta ha introdotto una nuova soluzione di intelligenza artificiale generativa che permette di trasformare il testo in musica, volendo anche in accordo con i temi e le caratteristiche di brani già esistente. Si chiama MusicGen ed è di fatto un’alternativa alla più conosciuta soluzione di Google nota come MusicLM. Funziona un po’ come gli altri modelli predittivi su cui si basano ChatGPT, Google Bard e simili, ma invece di utilizzare un sistema in grado di predire la parola o il carattere che segue il precedente, lo fa con la musica.
Entrando più nello specifico, i colleghi di The Decoder spiegano che MusicGen si basa sulla scomposizione dei dati audio in parti più piccole (token: cioè una sequenza di informazioni digitali) tramite EnCodec di Meta. Alla base ci sarebbe un catalogo di circa 10 mila brani musicali in alta qualità, oltre ai contenuti derivati dalla piattaforma di immagini video e musica Shutterstock e da Pond5, un’azienda statunitense anch’essa che offre in licenza musica e altri contenuti.
MusicGen di Meta sarebbe stata addestrata per circa 20 mila ore con brani di vario tipo, allenamento che consente a questa IA di generare della musica a partire dai comandi testuali forniti dall’utente, testo che serve come insieme di istruzioni per impostare lo stile di base. E il bello è che è possibile anche chiederle di generare qualcosa che si combini o si ispiri a un brano già esistente.
Segui TuttoTech.net su Google Discover

Come provare MusicGen di Meta: esempi ed efficacia
Partiamo da un esempio piuttosto indicativo di un brano generato da MusicGen che combina la celebre toccata e fuga in Re minore (BWV 565) di Johann Sebastian Bach con vari comandi testuali resi e riprodotti in brevi parti da pochi secondi.
Le potenzialità sembrano interessanti già ad ascoltare questi esempi, merito del modello su cui si basa MusicGen da 1,5 miliardi di parametri, reputato migliore dagli ascoltatori umani rispetto a quelli da 300 milioni e da 3,3 miliardi, entrambi provati da Meta con quest’ultimo che sarebbe risultato tuttavia superiore in termini di qualità audio e di capacità di abbinare in maniera accurata gli input testuali con gli output audio, come si evince dallo schema che segue.
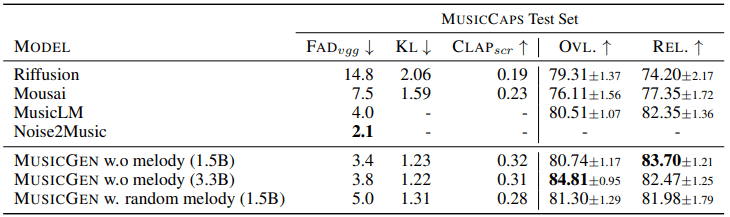
I dati che vedete nell’immagine qui sopra, dati condivisi dall’azienda di Mark Zuckerberg, mettono a confronto MusicGen di Meta e MusicLM di Google con altri modelli musicali simili come Riffusion, Mousai e Noise2Music; dove valori più bassi di FAD (Fréchet Audio Distance) indicano che l’audio generato è più attendibile, valori inferiori di KL (divergenza di Kullback-Leibler) segnalano che la musica generata è concettualmente simile alla musica di riferimento e il punteggio CLAP quantifica l’allineamento fra audio e testo. Se queste erano le metriche oggettive, per quanto riguarda invece quelle soggettive, cioè basate sulla percezione umana, il rapporto tiene conto della qualità complessiva (OVL) su una scala da 1 a 100, scala che vale anche per il parametro REL che indica la corrispondenza fra audio e testo. Dunque, secondo quanto emerso, questa soluzione di Meta è risultata superiore rispetto a MusicLM di Google, ma non agli altri modelli, considerando le sole metriche oggettive.
Comunque, l’azienda di Zuckerberg ha rilasciato il codice e i modelli in open source su GitHub (li trovate qui), disponibili anche per l’uso commerciale. Per provare MusicGen, potete invece andare su Hugging Face, descrivere il brano che desiderate generare (poco più in basso ci sono anche alcuni esempi) e caricare un file o trascinare nel box accanto un brano extra, se preferite farlo corrispondere a qualcosa di reale.
Potrebbero interessarti anche: Una fotocamera che scatta foto senza sensori? Sì, grazie all’intelligenza artificiale e NVIDIA Neuralangelo genera modelli 3D dai video registrati con lo smartphone
I nostri contenuti da non perdere:
- 🔝 Importante: AMD Ryzen 7 9700X vs Ryzen 7 9850X3D: ecco quanto conta la cache 3D a parità di core
- 💰 Risparmia sulla tecnologia: segui Prezzi.Tech su Telegram, il miglior canale di offerte
- 🏡 Seguici anche sul canale Telegram Offerte.Casa per sconti su prodotti di largo consumo