
Quando si parla di ricerca nel campo dell’intelligenza artificiale, il nome Apple non è il primo che viene in mente. Eppure negli ultimi mesi il team di ricerca di Cupertino ha intensificato gli sforzi per posizionarsi al centro di una nuova generazione di strumenti AI. Dopo esperimenti nel campo della visione artificiale e dei foundation model per la comprensione del linguaggio, la società ha annunciato la pubblicazione pubblica di Pico-Banana-400K, un dataset da 400.000 immagini pensato per addestrare modelli di editing testuale delle immagini.
Un’iniziativa che, a prima vista, potrebbe sembrare distante dal core business di Apple ma che in realtà si inserisce perfettamente nel suo ecosistema di innovazione legato a Apple Intelligence e alle future applicazioni creative su macOS e iPadOS.
Segui TuttoTech.net su Google Discover

Un dataset per colmare un vuoto nella ricerca
Il progetto nasce da una constatazione precisa: nonostante i progressi di colossi come Google e OpenAI, la ricerca open source soffre ancora di una mancanza strutturale di dataset di editing visivo di alta qualità. In molti casi, le collezioni disponibili sono parziali, costruite su generazioni sintetiche o limitate da licenze proprietarie. Questo frena lo sviluppo di modelli capaci di interpretare in modo coerente le richieste testuali dell’utente, mantenendo realismo e qualità estetica.
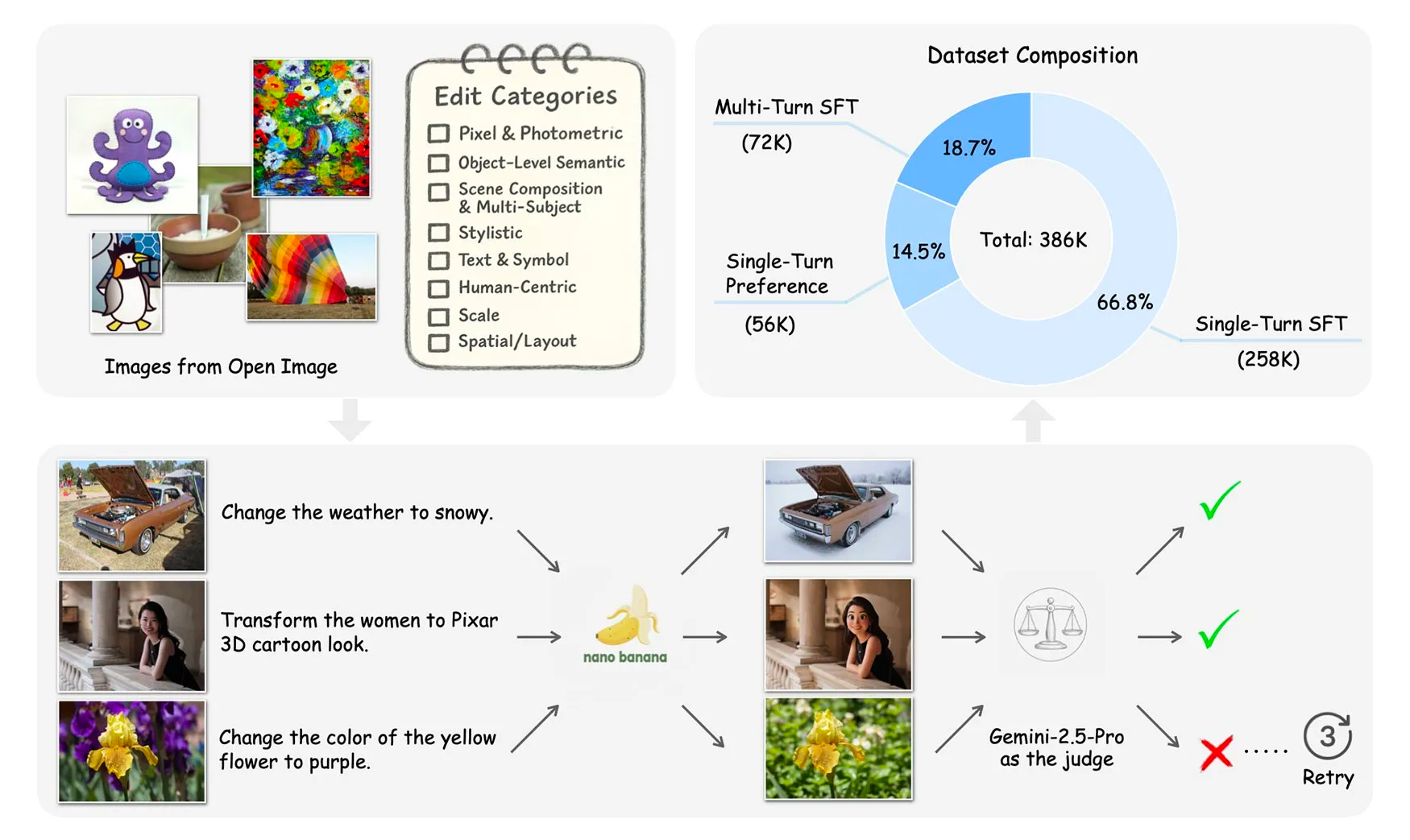
Con Pico-Banana-400K, il gruppo di ricerca di Apple ha voluto offrire una soluzione concreta. Le 400.000 immagini del dataset non sono semplici fotografie: ognuna di esse racconta un processo di editing controllato, descritto e validato, con l’obiettivo di diventare una risorsa di riferimento per accademici e sviluppatori.

Dietro le quinte: collaborazione (indiretta) con Google Gemini
La parte più sorprendente del progetto è il metodo di costruzione. Per generare gli esempi di editing, Apple ha utilizzato le capacità del modello di Google Gemini 2.5, nella sua versione “Flash Image”, nota internamente anche come Nano-Banana. In altre parole, un modello di Google ha prodotto le modifiche visive, mentre un modello superiore, Gemini 2.5 Pro, ha svolto il ruolo di revisore, approvando o scartando i risultati in base alla fedeltà alla richiesta e alla qualità visiva complessiva.
Questo approccio incrociato ha permesso di costruire un dataset pulito e bilanciato, con immagini che mostrano esempi chiari di editing ben riusciti e di risultati falliti. Quest’ultima categoria è particolarmente interessante per la formazione dei modelli, perché consente di apprendere anche dalle imperfezioni.
Il risultato finale è un insieme di immagini strutturato in tre tipologie principali:
- Single-turn edits: modifiche basate su un singolo prompt testuale.
- Multi-turn edits: sequenze iterative in cui l’immagine viene modificata più volte.
- Preference pairs: coppie di risultati buoni e meno riusciti, utili per addestrare modelli di preferenza e giudizio qualitativo.
Apple ha definito 35 categorie di cambiamento testuale suddivise in otto macro-aree. Tra le più rappresentative troviamo:
- Pixel & Photometric: interventi come l’aggiunta di grana cinematografica o filtri vintage.
- Human-Centric: trasformazioni ispirate a oggetti collezionabili, come la conversione di una persona in una figura in stile Funko Pop.
- Scene Composition & Multi-Subject: variazione delle condizioni ambientali, dal soleggiato al nevoso.
- Object-Level Semantic: spostamento o rilocazione di oggetti nella scena.
- Scale e Perspective: zoom, ritaglio e modifiche di inquadratura.
Questo schema consente di generare una base dati ampia e diversificata, in grado di coprire una grande varietà di contesti e richieste linguistiche. È un passo avanti importante rispetto ai dataset precedenti, che spesso soffrivano di una eccessiva omogeneità delle modifiche.
Licenza di ricerca e apertura controllata
Un altro punto rilevante è la licenza. Pico-Banana-400K è rilasciato con una licenza di ricerca non commerciale, il che significa che università, laboratori e centri di sviluppo possono utilizzarlo liberamente per fini scientifici, ma non per applicazioni commerciali. È lo stesso approccio che Apple aveva adottato con i suoi dataset di visione artificiale dedicati alla segmentazione e al riconoscimento degli oggetti pubblicati negli anni scorsi.
In sostanza, Cupertino intende favorire la ricerca aperta senza però permettere che i risultati vengano integrati direttamente in servizi commerciali da parte di terzi. Una scelta coerente con la filosofia di equilibrio tra privacy, apertura accademica e controllo del proprio ecosistema.
Dalla ricerca alle applicazioni pratiche
Al di là del valore scientifico, l’iniziativa apre prospettive interessanti anche sul fronte del prodotto. È facile immaginare che Apple possa utilizzare la conoscenza derivata da Pico-Banana-400K per potenziare strumenti di editing basati su linguaggio naturale all’interno di app come Foto, Keynote o persino Final Cut Pro.
Negli ultimi mesi, Apple ha mostrato un chiaro interesse per funzionalità AI di alto livello: dalla segmentazione semantica dei soggetti in iOS 18 fino alle funzioni creative di Apple Intelligence presentate alla WWDC 2025. Il dataset appena pubblicato rappresenta un tassello perfettamente coerente con questa strategia.
Nel medio periodo, Cupertino potrebbe combinare l’esperienza accumulata in ambito di visione artificiale con l’elaborazione locale su chip serie M e A, sviluppando strumenti di editing fotografico completamente on-device, senza necessità di cloud. Un approccio che garantirebbe velocità, sicurezza e privacy, tre valori centrali nella filosofia Apple.

Un contributo alla comunità AI che sorprende
L’arrivo di Pico-Banana-400K segna anche un momento di discontinuità culturale per l’azienda. Apple, tradizionalmente molto riservata sulle proprie ricerche interne, sta progressivamente aprendo i propri laboratori al mondo accademico, con pubblicazioni sempre più frequenti su arXiv e GitHub.
In un contesto dominato da giganti come Google DeepMind, OpenAI e Anthropic, Cupertino sceglie di posizionarsi come attore responsabile, concentrato su qualità dei dati, trasparenza e collaborazione accademica. Non un ingranaggio della corsa all’AI generativa, ma un contributo mirato alla costruzione di un’infrastruttura più solida e affidabile per il futuro dell’intelligenza artificiale visiva.
Il futuro dell’editing guidato dal testo
Il principale obiettivo di Pico-Banana-400K è quello di fungere da base di addestramento per la prossima generazione di modelli di image editing “text-guided”, in grado cioè di comprendere descrizioni naturali come “aggiungi atmosfera nebbiosa” o “sposta la persona al centro dell’immagine” e tradurle in azioni visive coerenti.
Oggi questo tipo di intelligenza si trova ancora in una fase di sperimentazione, ma dataset come quello di Apple rappresentano la chiave per il suo perfezionamento. Con più equilibrio nei dati, una catalogazione rigorosa e indicazioni di qualità validate, i modelli futuri potranno finalmente superare i limiti di coerenza spaziale e semantica evidenziati dagli approcci precedenti. Pico-Banana-400K non è solo un dataset: è un segnale chiaro della direzione verso cui Apple intende muoversi. Un ecosistema dove la creatività dell’utente incontra l’intelligenza artificiale con trasparenza, controllo e un pizzico di ambizione scientifica.
I nostri contenuti da non perdere:
- 🔝 Importante: Recensione Xiaomi Watch 5: autonomia superiore, prezzo giusto e a noi basta e avanza
- 💰 Risparmia sulla tecnologia: segui Prezzi.Tech su Telegram, il miglior canale di offerte
- 🏡 Seguici anche sul canale Telegram Offerte.Casa per sconti su prodotti di largo consumo