Quando si parla di intelligenza artificiale applicata alle immagini, uno dei temi più complessi e spesso sottovalutati è l’integrazione reale tra comprensione visiva, generazione e modifica all’interno di un unico sistema. Apple ha provato a rispondere proprio a questa sfida pubblicando una nuova ricerca che introduce UniGen 1.5, un modello IA multimodale in grado di vedere, creare e modificare immagini senza ricorrere a modelli separati.
Si tratta di un lavoro di ricerca, certo, ma che offre uno sguardo piuttosto interessante su come Cupertino stia impostando lo sviluppo dei suoi futuri sistemi di intelligenza artificiale.
Segui TuttoTech.net su Google Discover







Uno sguardo al futuro dell’IA di Apple con UniGen 1.5
Per capire UniGen 1.5 bisogna fare un passo indietro, lo scorso maggio un team di ricercatori Apple aveva pubblicato lo studio “UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation“, introducendo un modello linguistico multimodale unificato capace sia di comprendere le immagini sia di generarle, evitando l’uso di pipeline composte da più modelli specializzati.
L’idea di fondo era piuttosto chiara: un unico modello, addestrato correttamente, può sfruttare le capacità di comprensione visiva per migliorare anche la qualità della generazione.
Con il nuovo studio intitolato “UniGen-1.5: Improving Image Generation and Editing via Unified Reward Learning“, Apple compie un ulteriore passo avanti; UniGen 1.5 aggiunge ufficialmente la capacità di editing delle immagini, mantenendo però l’approccio unificato: comprensione, generazione e modifica convivono nello stesso framework.
Un obbiettivo tutt’altro che banale, perché (come sottolineano gli stessi ricercatori) comprendere un’immagine e modificarla secondo istruzioni complesse richiede strategie molto diverse, e proprio qui emergono alcune delle principali difficoltà degli attuali modelli di editing.
Secondo Apple, uno dei limiti più evidenti nei modelli di editing è la scarsa comprensione delle istruzioni, soprattutto quando le modifiche richieste sono minori o imperecettibili, le istruzioni sono molto specifiche e articolate, oppure quando è necessario preservare l’identità visiva dell’immagine originale.
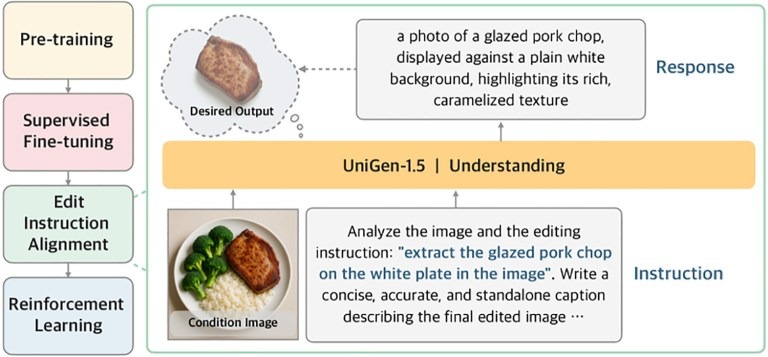
Per affrontare questo problema, UniGen 1.5 introduce una nuova fase di post-addestramento chiamata Edit Instruction Alignment; in pratica, prima di passare all’apprendimento per rinforzo, il modello viene addestrato a:
- ricevere in input l’immagine originale e le istruzioni di editing
- dedurre una descrizione testuale dettagliata di come dovrebbe apparire l’immagine finale
Questo passaggio intermedio aiuta il modello a interiorizzare meglio l’obbiettivo della modifica, migliorando l’allineamento tra istruzioni e risultato finale prima della generazione vera e propria.
Uno degli aspetti più interessanti del lavoro riguarda l’uso dell’apprendimento per rinforzo, Apple utilizza lo stesso sistema di ricompensa sia per la generazione che per l’editing delle immagini, superando un problema storico di questi modelli: le modifiche possono variare da piccoli ritocchi a trasformazioni radicali, rendendo difficile definire metriche coerenti.
Grazie a questo approccio unificato, UniGen 1.5 riesce a ottenere risultati molto competitivi nei benchmark di settore.
Nei test standard utilizzati per valutare capacità di seguire le istruzioni, qualità visiva e gestione di modifiche complesse, UniGen 1.5 eguaglia o supera diversi modelli multimodali all’avanguardia, sia open source che proprietari; nello specifico:
- 0,89 su GenEval e 86,83 su DPG-Bench, superando modelli come BAGEL e BLIP3o
- 4,31 su ImgEdit, meglio di soluzioni open source come OminiGen2 e paragonabile a modelli proprietari come GPT-Image-1
Numeri che, almeno sulla carta, collocano UniGen 1.5 tra le proposte più interessanti nel panorama della ricerca sull’IA multimodale.

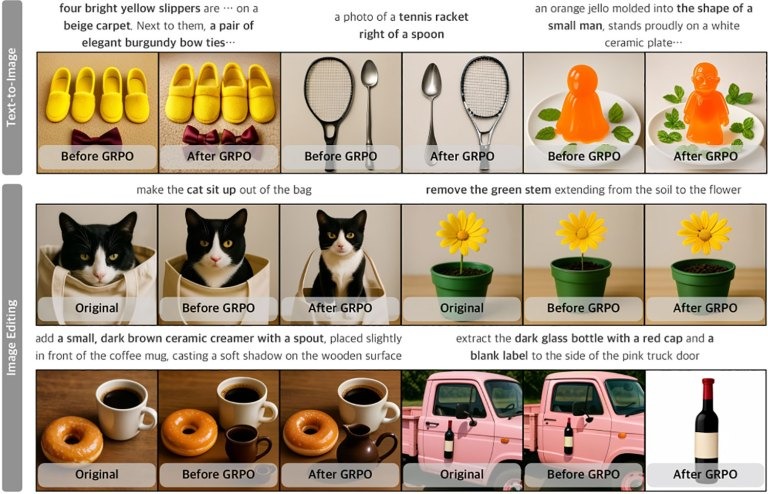
Ovviamente non è tutto perfetto, gli stessi ricercatori di Apple ammettono alcune criticità ancora presenti, in particolare difficoltà nella generazione accurata di testo all’interno delle immagini, nonché problemi di coerenza dell’identità visiva in alcuni scenari di editing (ad esempio variazioni involontarie nel pelo di un animale o nei colori di un soggetto).
Limiti legati soprattutto al controllo dei dettagli più fini, che richiederanno ulteriori miglioramenti nelle prossime interazioni del modello.

Al netto del linguaggio accademico, UniGen 1.5 rappresenta un segnale piuttosto chiaro, Apple sta investendo seriamente in modelli multimodali unificati, capaci di gestire più compiti senza frammentare l’intelligenza artificiale in sistemi separati.
Non è ancora chiaro quando, e in che forma, queste tecnologie arriveranno nei prodotti commerciali, ma è evidente che le basi teoriche e tecniche si stanno facendo sempre più solide e, come spesso accade, la ricerca di oggi potrebbe diventare la funzionalità magica di domani, magari integrata direttamente nell’ecosistema Apple.
- ChatGPT aggiorna le sue regole per gli under 18 con nuove protezioni dedicate agli adolescenti
- Adobe è stata accusata di aver utilizzato libri piratati per addestrare l’IA
- ChatGPT apre alle app: gli sviluppatori possono inviarle per la pubblicazione ufficiale
- OpenAI accelera su immagini e servizi: debutta GPT-Image-1.5 mentre Apple Music si prepara all’integrazione
I nostri contenuti da non perdere:
- 🔝 Importante: Recensione Amazon Kindle Scribe 2026: il più grande, più bello, più completo
- 💰 Risparmia sulla tecnologia: segui Prezzi.Tech su Telegram, il miglior canale di offerte
- 🏡 Seguici anche sul canale Telegram Offerte.Casa per sconti su prodotti di largo consumo