


I ricercatori di Apple hanno sviluppato un nuovo metodo per addestrare modelli di intelligenza artificiale dedicati alla descrizione delle immagini, ottenendo risultati più accurati e dettagliati pur utilizzando modelli di dimensioni notevolmente inferiori.
Lo studio, condotta in collaborazione con l’Università del Wisconsin-Madison, potrebbe accelerare significativamente l’addestramento delle future AI multimodali, affermano i ricercatori. Vediamo di cosa si tratta.
Indice:
Segui TuttoTech.net su Google Discover
Apple vuole risolvere il problema delle descrizioni dense
Lo studio, intitolato RubiCap: Rubric-Guided Reinforcement Learning for Dense Image Captioning, si concentra sul cosiddetto “dense image captioning”, ovvero la generazione di descrizioni dettagliate a livello di singole regioni dell’immagine, piuttosto che un semplice riassunto generale.
In pratica, il sistema identifica molteplici elementi e aree in un’immagine e li descrive con un livello di dettaglio molto più fine, producendo una comprensione della scena decisamente più ricca rispetto a una descrizione complessiva (come potete notare nell’immagine sottostante).
Il cosiddetto dense image captioning può essere utilizzato per una varietà di applicazioni, dall’addestramento di modelli vision-language e text-to-image al miglioramento della ricerca per immagini e degli strumenti di accessibilità.
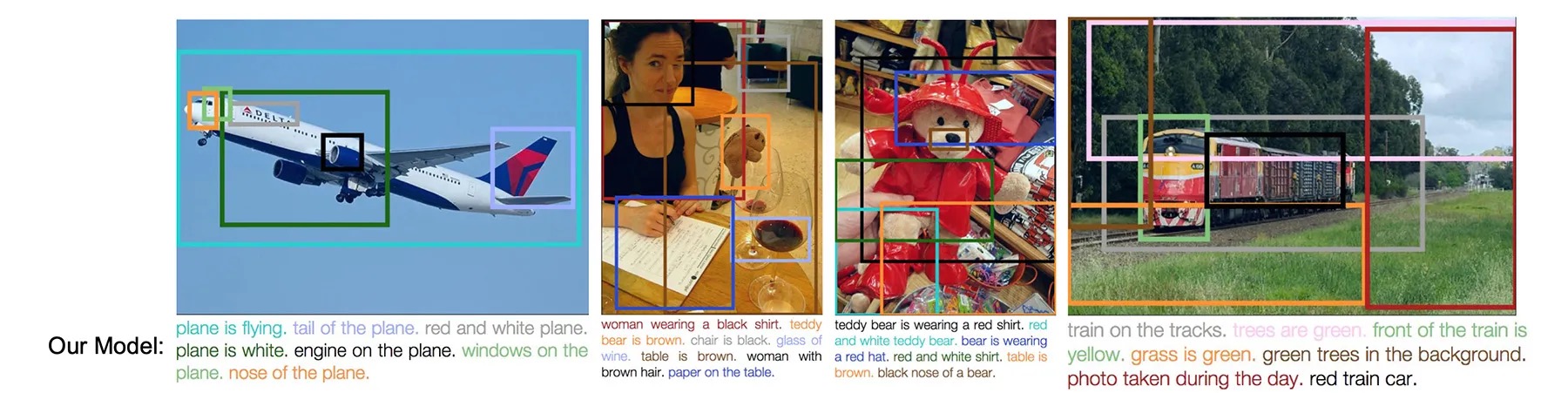

Il problema, secondo i ricercatori, è che gli approcci attuali basati sull’AI per addestrare questi modelli tendono a presentare limiti significativi. La scalabilità delle annotazioni di qualità è molto costosa, e mentre la generazione sintetica di didascalie tramite modelli vision-language potenti rappresenta un’alternativa pratica, la distillazione supervisionata spesso produce una diversità limitata negli output e una generalizzazione debole.
Come funziona RubiCap
Per affrontare questi limiti, i ricercatori hanno proposto un nuovo framework che adotta un approccio interessante. Hanno campionato casualmente 50.000 immagini da due dataset di addestramento, PixMoCap e DenseFusion-4V-100K.
Per ogni immagine, il sistema ha generato diverse opzioni di didascalia utilizzando una serie di modelli vision-language esistenti, tra cui Gemini 2.5 Pro, GPT-5, Qwen2.5-VL-72B-Instruct, Gemma-3-27B-IT e Qwen3-VL-30B-A3B-Instruct. Contemporaneamente, il modello in fase di addestramento con RubiCap produceva la propria didascalia per quella stessa immagine.
A quel punto, RubiCap utilizzava Gemini 2.5 Pro per analizzare l’immagine insieme alle didascalie candidate e all’output del modello, identificare su cosa i modelli concordavano e cosa era stato tralasciato o rappresentato in modo errato, e trasformare queste informazioni in criteri chiari per giudicare le didascalie.
Successivamente, Qwen2.5-7B-Instruct fungeva da giudice, assegnando punteggi alle didascalie rispetto a ciascun criterio per produrre il segnale di ricompensa utilizzato per l’addestramento. In questo modo, il modello riceveva un feedback più preciso e strutturato su cosa correggere, portando a didascalie più accurate senza fare affidamento su un’unica risposta “corretta”.
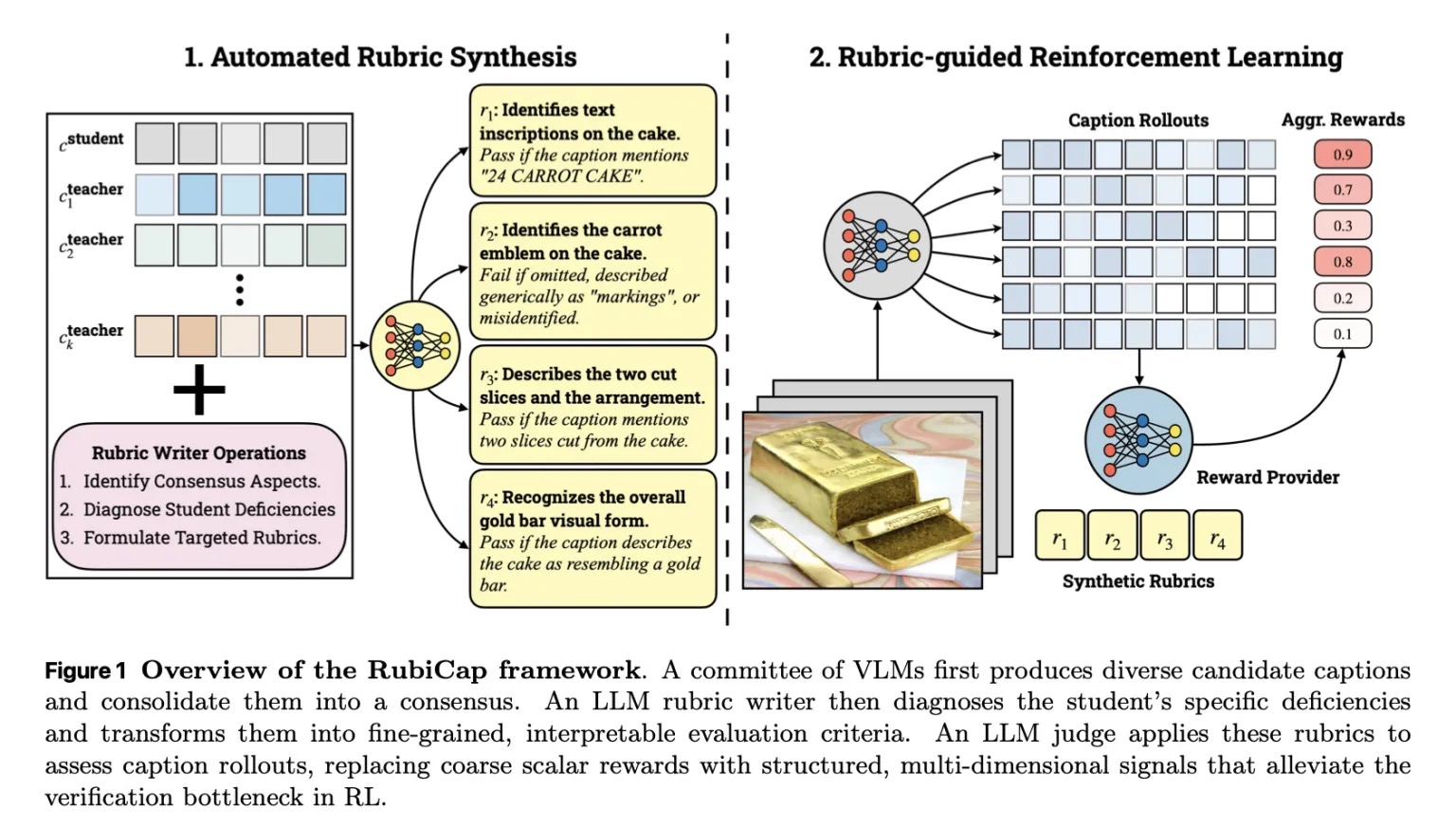

Risultati sorprendenti con modelli più piccoli
Il risultato finale sono tre modelli: RubiCap-2B, RubiCap-3B e RubiCap-7B, rispettivamente con 2, 3 e 7 miliardi di parametri. E rispetto agli approcci attuali, hanno ottenuto risultati sorprendentemente buoni, superando modelli con fino a 72 miliardi di parametri.
Secondo lo studio, RubiCap ha raggiunto i più alti tassi di vittoria su CapArena, superando la distillazione supervisionata, i metodi RL precedenti, le annotazioni di esperti umani e gli output potenziati con GPT-4V. Su CaptionQA, ha dimostrato un’efficienza delle parole superiore: il modello da 7B ha eguagliato Qwen2.5-VL-32B-Instruct, mentre il modello da 3B ha superato la sua controparte da 7B.
In una valutazione di ranking in cieco, RubiCap-7B ha ottenuto la più alta proporzione di assegnazioni al primo posto tra tutti i modelli, inclusi quelli da 72B e 32B, raggiungendo la penalità per allucinazioni più bassa e la migliore accuratezza.
Un aspetto particolarmente interessante è che il modello più piccolo da 3 miliardi di parametri ha superato la sua controparte più grande su alcuni benchmark, suggerendo che un modello efficace per il dense image captioning non richiede necessariamente una scala massiva per fornire risultati di alta qualità.
Per approfondire lo studio, inclusa un’analisi dettagliata dei termini tecnici utilizzati, è possibile consultare la ricerca completa.
I nostri contenuti da non perdere:
- 🔝 Importante: Lenovo Yoga Slim 7 con OLED e Intel Core Ultra 7 al minimo storico su Amazon: sconto del 50%
- 💰 Risparmia sulla tecnologia: segui Prezzi.Tech su Telegram, il miglior canale di offerte
- 🏡 Seguici anche sul canale Telegram Offerte.Casa per sconti su prodotti di largo consumo